

Our research paper entitled “An Optimized Pipeline for the Processing of Healthcare Data towards the Creation of Holistic Health Records” has been published in the context of the Proceedings of 2023 International Conference on Applied Mathematics & Computer Science (ICAMCS). The presentation of this paper was held on 9th of August 2023, in Lefkada, Greece.
In this paper, the challenging topics of data standardization and qualification have been examined that are of crucial importance, considering the heterogeneity and diversity of the nature and format that describe healthcare data. To further research those topics, in this paper a generalized and domain-agnostic pipeline was proposed that assures the incoming data’s accuracy, integrity, and quality, while also providing a decision on whether a connected data source will be considered reliable or not. On top of this, the introduced pipeline improves data interoperability by employing automated harmonization and standardization techniques on the data after they have been efficiently cleaned and qualified. The utilization of this pipeline ensures that data are consistently presented, regardless of their source. The latter speeds up the decision-making processes and increases productivity as well as efficiency of the modern healthcare stakeholders as it also fosters the integration of primary and secondary data.
The proposed pipeline addresses these aspects by exploiting three (3) processing phases, the cleaning, the qualification, and the harmonization of the data. These phases are realized through the design and implementation of three (3) integrated subcomponents, i.e., the Data Cleaner, the Data Qualifier, and the Data Harmonizer respectively as depicted in Fig. 1 and in the context of the iHelp project.
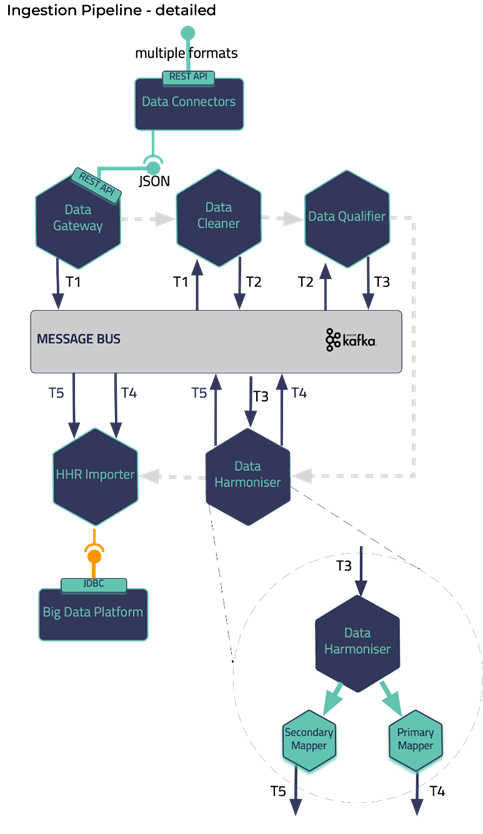
In deeper detail, as soon as all the needed data are ingested into this pipeline by a collection mechanism, such as Data Gateways, the first two phases of this pipeline are the cleaning and quality assurance of the collected data. Thus, from the very beginning of the overall processing pipeline, it aims to clean all the collected data and to measure and evaluate the quality of both the connected data sources and their produced data. To successfully achieve that, the optimized pipeline exploits two (2) separate modules, the Data Cleaner subcomponent, and the Data Qualifier subcomponent. Sequentially, in the harmonization phase, the interpretation and transformation of the collected cleaned, and reliable data takes place through the implementation and utilization of the Data Harmonizer. The latter incorporates two (2) subcomponents, the Terminology Mapping service, and the Data Mappers to further transform the cleaned and reliable data and to provide interoperable, harmonized, and transformed into the HL7 FHIR standard data. To this end, the proposed pipeline facilitates the standardization and qualification of the heterogeneous primary and secondary data coming from multiple health-related sources and provides data into a unique and globally recognized standard and format as the HL7 FHIR. Finally, the data are then fed into enhanced mappers to further transform them into the Holistic Health Records (HHRs) format, as it has been realized and introduced in the context of the iHelp project.




