

One of the most important technological building blocks of the iHelp platform is the data pipeline that captures the various types of data and ingests the information into the big data management platform of the iHelp platform. This blog presents the overview of such data pipelines and provides the basic design decisions and principles of their implementation. To start, we need to distinguish among the different aspects related to the data pipelines. On one hand, there are software components that take care of the actual capture of the data that resign in different sources. Secondly, there are the software components that do a pre-processing or transformation. These implement a specific business logic that can be packaged into a function or micro-service and are used to enhance or transform the raw data that has been initially pushed to the deployed data pipeline by the data capture components. In iHelp, they either provide data quality assurance by cleaning or harmonizing the ingested datasets or transforming the latter to the common HHR data model.
Regarding the software components related to the data capture aspects, there is the need to access, retrieve and finally push raw data into the data pipeline. The raw data in the eHealth domain can be in different structures (i.e., a CSV file that contains comma-separated values, a relational database where each data item can be stored in separate data tables, JSON files, etc.), and in different data schemas. Regarding the software components that formulate the data ingestion pipelines, we distinguish them into two major categories: The ones that are domain/ schema-agnostic and those that are not. An additional type of function is one that is related to the transformation of the raw data into the iHelp common data model, the HHR. However, this can be considered a subcategory of the domain/schema-specific functionalities. This categorization is important as it will define whether each data function will be placed inside the deployed data ingestion pipeline. The reason for this is evident from the different schemas of the raw data.
Schema agnostic functions or microservices can be applied in whatever type of an incoming dataset. An example can be a rule-based cleaning algorithm that checks if the values of specific metrics are valid or incorrect. On the other hand, an implementation of a function that provides quality assurance might be more sophisticated and might need to correlate information from different columns over a specific period of time. For such an implementation, there might be the need to know the schema of the incoming dataset in order to be able to retrieve the corresponding information to feed the AI analytical algorithm. As a result, it cannot be applied to whatever dataset that contains raw data, as opposed to our previous example.
In order to cope with these aspects, the iHelp project defines a common data model that will be used: the Holistic Health Record (HHR). Having a common data model in place will allow for all data analytical algorithms, which include those involved in the data ingestion pipelines, to rely on a common schema. Therefore, they can be implemented once and make use of the global data model of iHelp, instead of having the need to implement such functionalities differently for each incoming dataset. With iHelp’s integrated health records that define the HHR, each data analyst or data developer can know beforehand which is the schema and can have a single implementation for all types of incoming datasets. However, it is required that there must be a data transformation of the incoming datasets that contain raw data to the common data model of iHelp. These functionalities are domain-specific and need to be written for each of the supported datasets.
Having provided the basic principles of the components that are related to the data capture and ingestion pipelines, the following figure depicts the overview conceptual diagram of our solution.
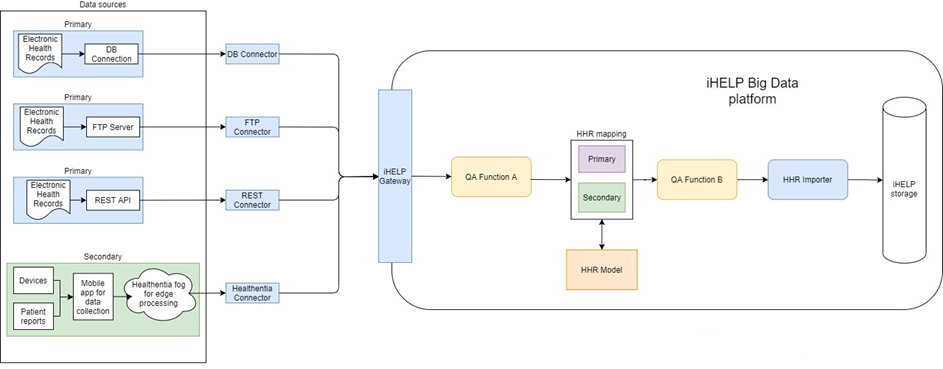
In a follow-up blog, we’ll provide more details about the basic principles behind each of the fundamental pillars of our architecture: the iHelp Gateway, the schema-agnostic/specific functions, the data mappers, along with information about the overall deployment and interconnection of these building blocks of our data ingestion pipelines.




