

In our previous blog, we presented an overview of how the data ingestion pipelines of the iHelp platform have been implemented. We gave information about the design principles of our architecture and we highlighted the main building blocks. In this blog, we will give more details about each one of those architectural pillars of the iHelp data ingestion pipelines.
The conceptual diagram of our solution, as presented in the previous blog, can be divided into two parts: The part that is placed left to the iHelp Gateway and can be considered as external to the integrated solution, and the part that is placed right to the Gateway which can be considered as part of the iHelp Big Data Platform itself. In the left part, we can see the various types of data sources that contain the raw data that need to be ingested inside the iHelp platform and eventually reach persistent storage.
The iHelp Gateway, or data capture mechanism, is the frontier of the overall integrated solution and is responsible for capturing different types of data. The data capture mechanism implements all functionalities related to the data capture aspects of the integrated data pipelines and it provides different types of connectors to each of the supported storage mediums. This is the reason why we provide a holistic approach for capturing data that will be further ingested by the data ingestion pipeline.
Regarding the functionalities that will formulate the data ingestion pipelines, they are considered as internal to the overall integrated solution of the iHelp platform and have been placed right next to the gateway. An important category of such functions is the one that is responsible for the transformation of the raw data to the common data model. In Figure 1, they are listed as primary and secondary mappers. These mappers will take input from the previous functions in a raw data format and by consulting the definition of the common HHR data model, they will convert the raw data to HHR data entities. As the big data repository is using a relational schema that is compliant with the HHR conceptual model, it is an obligation for the data pipeline to contain one function of this category. Each supported dataset will require the implementation of a dataset-specific HHR mapper that will be responsible for the data conversion task.
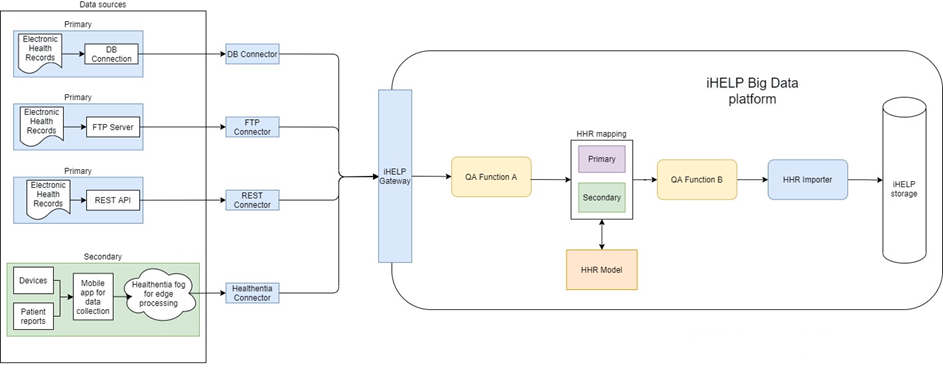
Between the data capture mechanism and the HHR Mappers, there are functions that implement algorithms that are domain/ schema-agnostic. These functions can take as an input raw data being ingested in the data pipeline by the Gateway and they will send as an output the same raw data with respect to their initial schema. Therefore, an important requirement is that they do not change the schema of the raw data, as the initial schema will be important for the HHR Mappers. As it has been described, these functions do not need to know about the schema of the data that they are being applied to and might only need to accept some input parameters in order to appropriately instantiate themselves so that they can be in place to know how to treat the incoming data.
Moreover, after the transformation of the raw data to the common HHR model that has been done by the corresponding HHR Mappers, there will be deployed all the functions that implement algorithms that are domain/schema specific. As it has been described, they must rely on the common HHR data model and they must accept data items transformed into this schema and send as an output data also compliant with the HHR. As they will be placed inside the established data pipeline after the HHR Mappers, this ensures that they will always receive data objects that are compliant with the HHR and therefore, they do not need to accept any schema-specific information to instantiate themselves, apart from function-specific parameters.
Finally, the last part of the deployed data pipelines will always be the HHR Importer, whose responsibility is to accept data items in the HHR common data model and store this information in the data store. This will hide all internal complexities of the implementing database-specific data connectivity mechanisms, and as a matter of fact, it can accept data items in the same fashion as all the aforementioned functions and place them into the Big Data Platform to persistently store them.
Last but not least, there are aspects related to the deployment of the data capture and ingestion pipelines and their establishments and interconnectivity during the runtime. It has been decided that the basic design principle will be the service choreography[1], which allows for loosely-coupled microservices that can communicate with each other according to the data pipeline they are involved in. The data will be exchanged using Kafka queues. This means that after the initial capture of the raw data from the Gateway, the data items will be placed inside a specific Kafka topic. Then, each of the data functions involved in the data pipeline that needs to be established will read data from one Kafka topic and will place the output into another Kafka topic, so that the next involved function can retrieve it. At the end of the data pipeline, the HHR importer will consume data from a specific data topic in a similar way and will connect to the Big Data Platform to persistently store the data.
[1] https://en.wikipedia.org/wiki/Service_choreography




